3.1 Técnicas de Clustering
La mayoría de las técnicas de aprendizaje no supervisado son una forma de análisis por cluster.
En análisis por cluster, los datos son divididos en grupos de acuerdo con alguna métrica de similaridad o característica compartida. De esta forma los objetos o instancias en el mismo clúster son muy similares y los de distintos muy diferentes.
Los algoritmos de clustering se dividen en dos grandes grupos5:
Clustering rígido, donde cada dato pertenece únicamente a un clúster.
Clustering suave, donde cada dato puede pertenecer a más de un clúster.
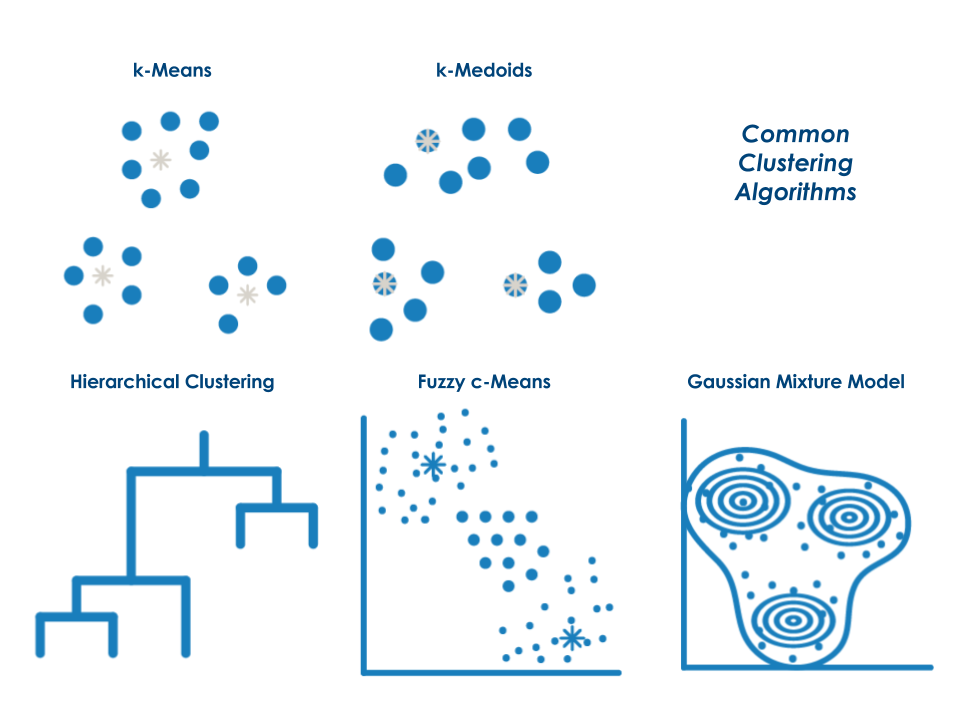
k-means
¿Cómo trabaja? Particiona datos en k número de clusters mutuamente excluyentes. El como de bien un punto se ajuste a un clúster determinado viene dado por su distancia al centro de dicho clúster.
¿Cuándo se usa? Cuando el número de clusters es conocido y cuando se requiere un clustering rápido de grandes conjuntos de datos.
¿Cuál es el resultado? Centroide de cada cluster.
k-medoids
¿Cómo trabaja? Algoritmo similar a k-medias pero requiere de que los centroides sean puntos u observaciones de la muestra.
¿Cuándo se usa? Cuando el número de clusters es conocido. Para clustering rápido de datos categóricos. Para escalar a grandes conjuntos de datos.
¿Cuál es el resultado? Observación o individuo de la muestra que actúa de centroide o medoide de cada cluster.
Hierarchical Clustering
¿Cómo trabaja? Produce conjuntos anidados de datos analizando similaridades entre pares de puntos y agrupando objetos en un arbol binario jerárquico.
¿Cuándo se usa? Cuando se desconoce el número de clusters a los que darán lugar los datos. Cuando se requiere de visualización para guiar la elección.
¿Cuál es el resultado? Dendograma mostrando la relación jerárquica entre los clusters.
Self-Organizing Map
¿Cómo trabaja? Red neuronal basada en clustering que transforma un conjunto de datos en un mapa 2D con preservación de topología.
¿Cuándo se usa? Para observar datos de alta dimensionalidad en mapas 2D o 3D. Para deducir la dimensionalidad de los datos preservando su topología (forma).
¿Cuál es el resultado? Representación en dimensión más baja (típicamente en 2D)
Fuzzy c-Means
¿Cómo trabaja? Agrupamiento difuso. Agrupamiento basado en particiones en el que los datos pueden estar en más de un cluster.
¿Cuándo se usa? Cuando el número de clusters es conocido. Para reconocimento de patrones. Cuando los clusters se sobreponen o se solopan.
¿Cuál es el resultado? Centro de los clústers (similar a k-means) pero con difusión (fuzziness) de forma que las observaciones o individuos pueden pertenecer a más de 1 cluster.
Gaussian Mixture Model
¿Cómo trabaja? Modelo gaussiando mixto. Agrupación basada en particiones en la que los datos provienen de diferentes distribuciones normales multivariantes con ciertas probabilidades.
¿Cuándo se usa? Cuando un punto puede pertenecer a más de un clúster. Cuando los clusters diferentes tamaños y correlaciones entre ellos.
¿Cuál es el resultado? Modelo de distribuciones gausianas que proporciona la probabilidad de que una observación o individuo pertenezca a un clúster.