Capítulo 10 Aprendizaje Supervisado
Los modelos de la estadística tradicional (regresiones lineales, por ejemplo) suelen ser poco flexibles por su naturaleza paramétrica, es decir, estos modelos se construyen partiendo de u nas hipótesis y que, si estas no se cumplen, el modelo falla estrepitosamente.
Por ejemplo, una regresión lineal supone que la estructura de los datos sigue una tendencia lineal.
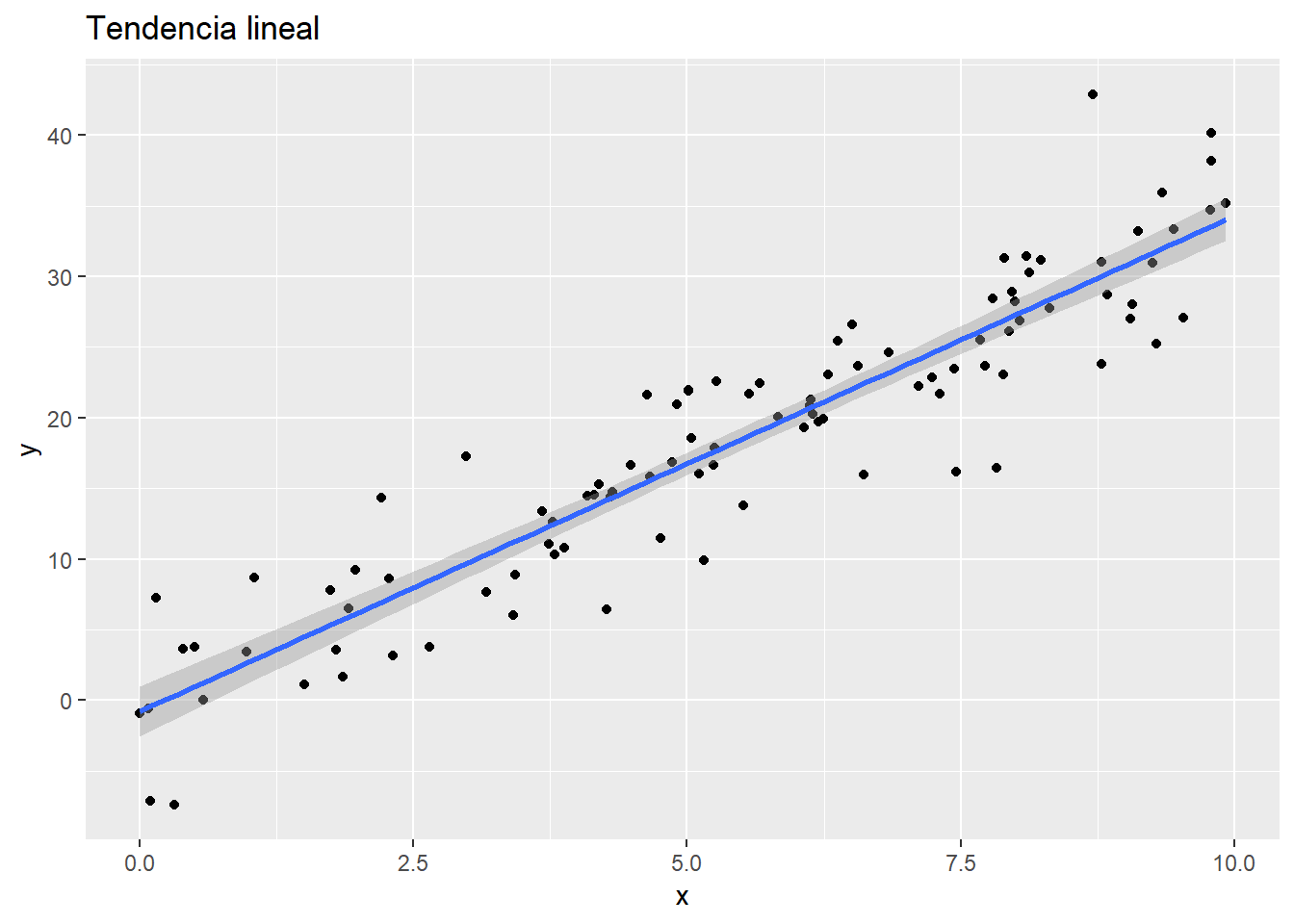
Si la estructura de los datos no sigue la hipótesis de linealidad, el modelo lineal es inservible en este caso
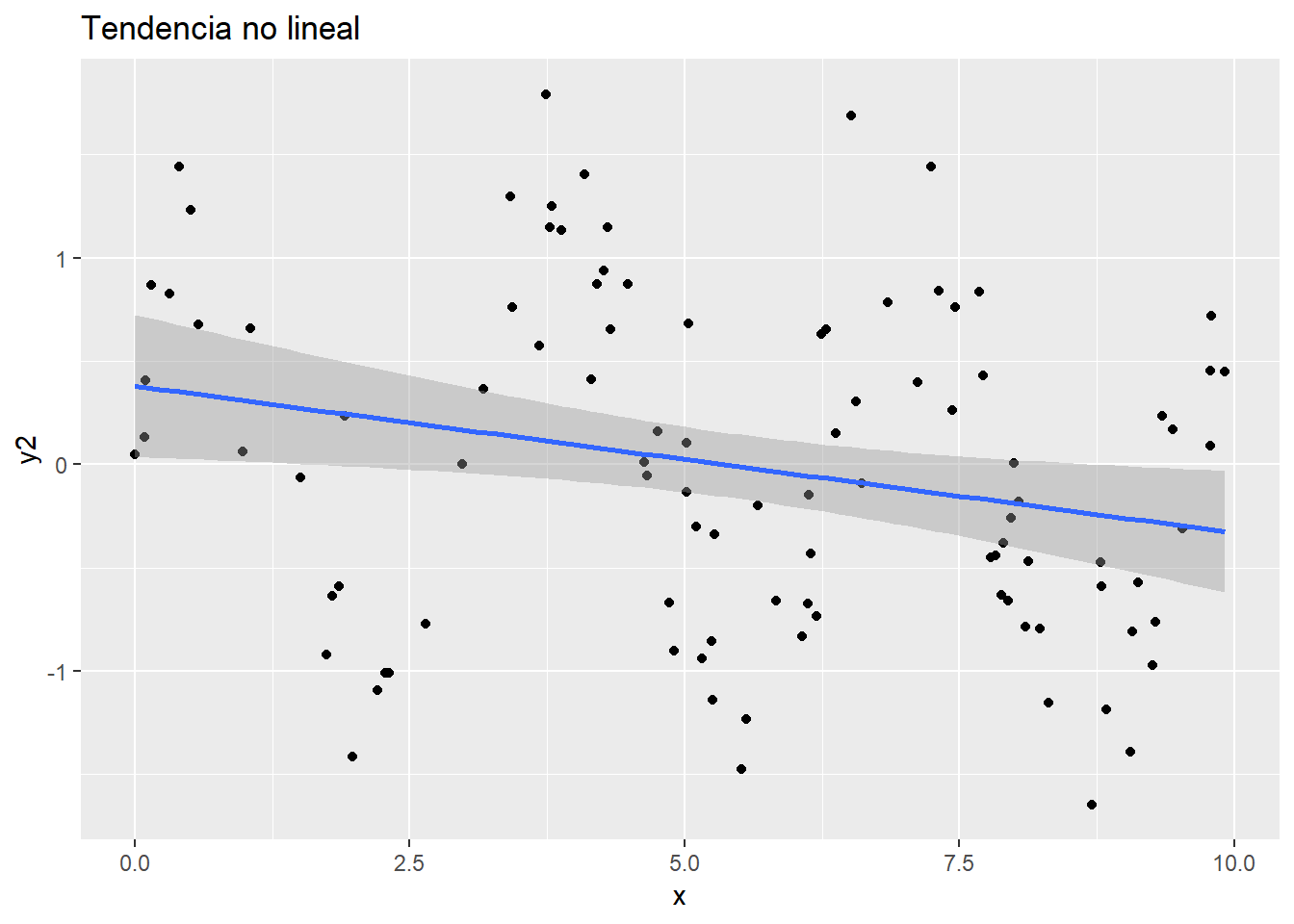
Los métodos propios del machine learning intentan ser métodos flexibles que permitan adaptarse a estructuras sin imponer hipótesis rígidas.
Una de las ideas más potentes y que más éxito ha tenido es la de los modelos ensamblados Estos modelos consisten en utilizar algún tipo de modelo que a priori pueda ser débil (como un árbol de decisión) y ensamblar distintos modelos con algún tipo de modificación en el que cada uno enfatice alguna característica.
Los modelos ensamblados (ensemble learning) que más uso tienen son:
- Bagging (bootstrap aggregating)
- Random Forest
- Boosting
Estos tres modelos utilizan los árboles de decisión como algoritmo base, así que primero vamos a hablar sobre ellos.