3.2 Técnicas de Clasificación
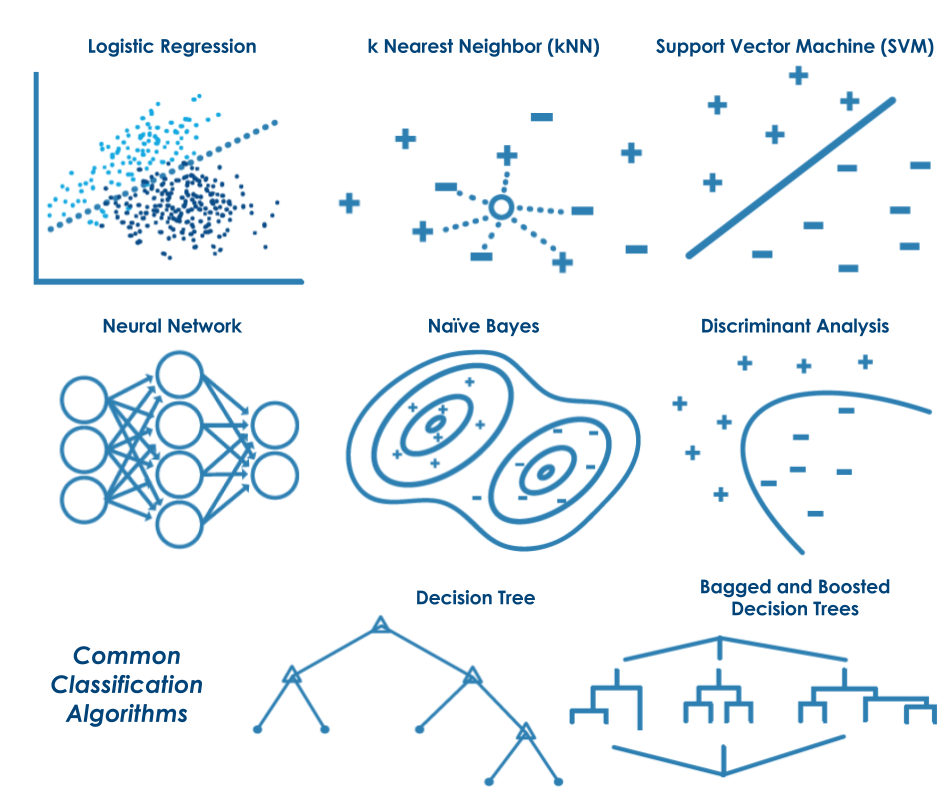
Regresión Logística
¿Cómo trabaja? Ajusta un modelo que puede predecir la probabilidad de que una respuesta binaria pertenezca a una clase u otra. Debido a su simplicidad, la regresión logística se utiliza comúnmente como punto de partida para los problemas de clasificación binaria.
¿Cuándo se usa? Cuando los datos se pueden separar claramente por un solo límite lineal. Como una línea de base (baseline) para evaluar más complejos métodos de clasificación.
k Vecinos Cercanos (kNN)
¿Cómo trabaja? kNN categoriza los objetos en función de las clases de su vecinos más cercanos en el conjunto de datos. Las predicciones de kNN suponen que los objetos cercanos entre sí son similares. Algunas de las métricas de distancia utilizadas para encontrar el vecino más cercano son: Euclides, bloque de la ciudad_city block, coseno y Chebychev.
¿Cuándo se usa? Cuando se requiere un algoritmo simple para establecer reglas de aprendizaje de referencia o base. Cuando el uso de memoria del modelo entrenado no es una preocupación. Cuando la velocidad de predicción del modelo entrenado tampoco constituye una limitación.
Support Vector Machines (SVM)
¿Cómo trabaja? Clasifica datos encontrando el límite de decisión lineal (hiperplano) que separa todos los puntos de datos de una clase de los de la otra clase. El mejor hiperplano para una SVM es aquel con el mayor margen entre las dos clases, cuando los datos son linealmente separables. Si los datos no son linealmente separables, se utiliza una función de pérdida para penalizar los puntos en el lado equivocado del hiperplano Los SVM a veces usan una transformación de núcleo para transformar los datos no separables linealmente en dimensiones más altas donde un límite de decisión lineal puede ser encontrado.
¿Cuándo se usa? Para datos que tienen exactamente dos clases.Para datos de alta dimensión, no linealmente separables.Cuando se necesita un clasificador que sea simple, fácil de interpretar y preciso.
Redes Neuronales
¿Cómo trabaja? Inspirada en el cerebro humano, una red neuronal consiste enredes de neuronas altamente conectadas que relacionan las entradas a las salidas deseadas La red se entrena de forma iterativa, modificando las fortalezas de las conexiones para que las entradas se asignen a la respuesta correcta.
¿Cuándo se usa? Para modelar sistemas altamente no lineales. Cuando los datos están disponibles de forma incremental y se desea actualiza constantemente el modelo. Cuando podría haber cambios inesperados en su datos de entrada. Cuando la interpretabilidad del modelo no es una preocupación importante.
Árboles de Decisión
¿Cómo trabaja? Un árbol de decisión permite predecir respuestas a datos siguiendo las decisiones organizadas en un árbol, desde la raíz (inicio) hasta un nodo u hoja. Un árbol consiste en condiciones organizadas en forma de ramificaciones, donde el valor de un predictor se compara con un peso entrenado. Los número de ramas y los valores de los pesos se determinan en el proceso de entrenamiento. Algunas acciones adicionales, como la poda, se pueden usar para simplificar el modelo.
¿Cuándo se usa? Cuando se necesita un algoritmo fácil de interpretar y rápido de ejecutar. Para minimizar el uso de memoria. Cuando la precisión predictiva alta no es un requisito.
Bagging, Boosting
¿Cómo trabaja? Varios árboles de decisión “más débiles” son combinados en un conjuto “más fuerte”. Un árbol de decisión en bolsas (bagging) consta de árboles entrenados de forma independiente en los datos que se remuestrean (boostrapping) a partir de los datos de entrada. Boosting implica crear un modelo fuerte mediante la adición iterativa de modelos “débiles” y ajustando el peso de cada modelo débil para centrarse en ejemplos mal clasificados.
¿Cuándo se usa? Cuando los predictores son categóricos (discretos) o se comportan no lineal.
Análisis Discriminante
¿Cómo trabaja? Clasifica los datos a partir de combinaciones lineales de los inputs. El análisis discriminante asume que las diferentes clases de datos se pueden generar a partir de distribuciones gaussianas. Entrenar o ajustar un modelo de análisis discriminante implica encontrar los parámetros para la distribución gaussiana de cada clase.
¿Cuándo se usa? Cuando necesitas un modelo simple que sea fácil de interpretar. Cuando el uso de la memoria durante el entrenamiento es una preocupación. Cuando necesitas un modelo que sea rápido para predecir.