3.6 ¿Qué técnica utilizar?
Elegir el algoritmo adecuado puede parecer abrumador—hay docenas de algoritmos de statistical learning, y cada uno tiene una aproximación diferente. No existe un único mejor método o uno que sirva para todos los casos. Buscar el adecuado es a veces una tarea de prueba y error—incluso los científicos de datos con más experiencia no pueden saber si un algoritmo funcionará sin haberlo probado. La selección del algoritmo también depende del tamaño y del tipo de los datos con el que se está trabajando, los resultados que se quieren obtener y como dichos resultados serán usados.
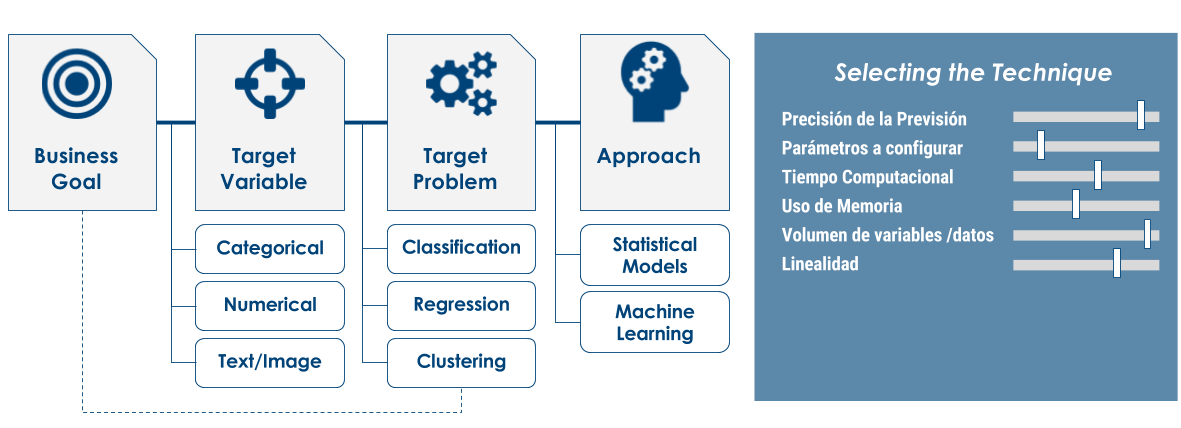
El primer paso, y uno de los más importantes, es definir el objetivo del análisis que se va a realizar. Volviendo al esquema propuesto por Marr (2017) (presentado en 1.1), Start with Strategy implica que, antes de empezar con los datos, se empiece con la definición de los objetivos de negocio que se quieren alcanzar. Inmediatamente después se definen los datos y las métricas que estarán involucradas.
En este momento se conoce la naturaleza del problema y de la variable objetivo, por lo tanto se conoce si estamos delante de una variable continua o binaria, si se requiere de un modelo explicativo, si sólo se requiere una segmentación, etc.
En consecuencia, una vez conocida la decisión que se requiere tomar y la variable objetivo que se analizará, se puede elegir el enfoque y modelo especíco que se va a utilizar.
Algunas situaciones donde este enfoque es útil son:
- Proceso de concesión de créditos, con modelos supervisados por la entidad reguladora.
- Asignación de presupuesto anual de marketing
- Determinación de metas de venta por distribuidor, centro, etc.
Considera usar el machine learning cuando se tenga una tarea compleja o un problema que involucre una gran cantidad de datos o variables, pero no exista fórmula o ecuación.
Por ejemplo, machine learning es una buena opción si se requieren manejar situaciones como:
- Las reglas y ecuaciones de escritura a mano son muy complejas—como reconocimiento facial o de voz.
- Las reglas de las tareas están cambiando constantemente—como en detección de fraude desde los registros de transacciones.
- La naturaleza de los datos es cambiante y el programa necesita adaptarse—como en el trading automático, previsión de demanda de energía y predicción de tendencias en compras.
Algunas consideraciones al elegir un algoritmo son6:
Precisión
No siempre es necesario obtener la respuesta más precisa posible. A veces, una aproximación ya es útil, según para qué se la desee usar. Si es así, puede reducir el tiempo de procesamiento de forma considerable al usar métodos más aproximados. Otra ventaja de los métodos más aproximados es que tienden naturalmente a evitar el sobreajuste.
Tiempo (de entrenamiento)
La cantidad de minutos u horas necesarios para modelizar varía mucho según el algoritmo. A menudo, el tiempo depende de la precisión (generalmente, uno determina al otro). Además, algunos algoritmos son más sensibles a la cantidad de datos que otros. Si el tiempo es limitado, esto puede determinar la elección del algoritmo, especialmente cuando el conjunto de datos es grande.
Cantidad de parámetros
Los parámetros son los botones que el analista activa al configurar un algoritmo. Son números que afectan al comportamiento del algoritmo, como la tolerancia a errores o la cantidad de iteraciones, o bien opciones de variantes de comportamiento del algoritmo. El tiempo de entrenamiento y la precisión del algoritmo a veces pueden ser muy sensibles y requerir solo la configuración correcta. Normalmente, los algoritmos con muchos parámetrosla mayor cantidad de pruebas para encontrar una buena combinación. La ventaja es que tener muchos parámetros normalmente indica que un algoritmo tiene mayor flexibilidad. Se puede lograr una precisión muy alta, siempre y cuando se encuentre la combinación correcta de configuraciones de parámetros.
Cantidad de variables
Para ciertos tipos de datos, la cantidad de variables o características puede ser muy grande en comparación con la cantidad de datos. Este suele ser el caso de la genética o los datos textuales. Una gran cantidad de características puede trabar algunos algoritmos y provocar que el tiempo de procesamiento sea demasiado largo.
Linealidad
Muchos algoritmos hacen uso de la linealidad. Los algoritmos de clasificación lineal suponen que las clases pueden estar separadas mediante una línea recta (o su análogo de mayores dimensiones). Entre ellos, se encuentran la regresión logística y las máquinas de vectores de soporte (svm). Los algoritmos de regresión lineal suponen que las tendencias de datos siguen una línea recta. Estas suposiciones no son incorrectas para algunos problemas, pero en otros disminuyen la precisión.
Casos especiales
Algunos algoritmos hacen determinadas suposiciones sobre la estructura de los datos o los resultados deseados. Si encuentra uno que se ajuste a sus necesidades, este puede ofrecerle resultados más útiles, predicciones más precisas o tiempos de procesamiento más cortos.
References
Marr, Bernard. 2017. Big Data: Using Smart Big Data, Analytics and Metrics to Make Better Decisions and Improve Performance. John Wiley & Sons.
Considera utilizar un modelo estadístico si se debe priorizar el poder explicativo, se dispone de tiempo computacional y memoria para ajustar modelos relativamente complejos.